Raft 算法是目前应用广泛的分布式共识算法,在许多知名的开源项目比如 etcd 中,都有 Raft 的身影。同时,随着 MIT6.824 课程的普及,Raft 俨然成为了最广为人知的分布式共识算法。
Raft 的设计动机之一就是为解决 Paxos 算法的难以理解性,因此 Raft 的一个大的特性就是易于理解。
直接啃论文是困难的,本文旨在以简洁的文字总结 Raft 算法,让第一次认识 Raft 算法的同学也可以很快有一个整体上的理解。
Raft is a consensus algorithm for managing a replicated log.
上面这句话引自 Raft 论文,即 Raft 是一个用于管理复制式日志的共识算法。
这里有两个问题,什么是复制式日志?什么是共识?
复制式日志( replicated log )
与复制式日志紧密相关的一个概念是 复制式状态机( Replicated state machines )
复制式状态机 用于解决分布式系统中的 容错( fault tolerance ) 问题,通常采用 复制式日志 实现,这里的容错是如何解决的呢?复制!日志中包含了对系统或者数据的操作(类似于 Mysql 的 undo log、redo log 等等),当日志只应用于单个节点上时,会有单点故障问题,一旦这个节点挂了,那么我的数据或者服务也就挂掉了;但是如果在多个节点上复制同样的日志,做同样的操作,那么即使有节点挂掉了,别的节点还在,我的数据或者服务依然可以为客户端所用,这使得整个系统具备了一定的容错性(除非所有保存相同日志的节点同时都挂了,但概率微乎其微)。
共识( consensus )
共识问题是分布式系统中的核心问题,通俗来讲,共识 指:
Several computers (or nodes) achieve consensus if they all agree on some value.
许多计算机(或者节点)都认可同一个值,那么称他们达成了共识。
那么如何让这么多的节点都认可同一个值呢?像 Raft 这样的共识算法就是为此而设计的。
如图所示,这是一个 复制式状态机 的示意图:
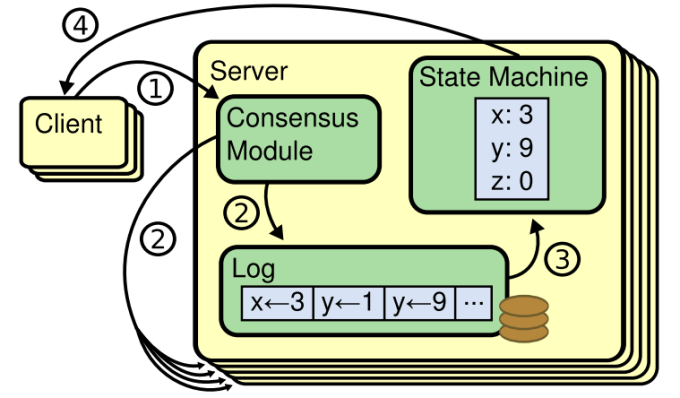
它包含 共识模块(Consensus Module) 、日志(Log) 以及 状态机(State Machine) 。它的具体工作流程如下,首先客户端与 共识模块 通信提交日志,随后 共识模块 将日志复制到其他节点的 复制式状态机 中,最后所有节点将日志提交给状态机执行。
这里的 共识模块 采用的就是 Raft 这样的共识算法,它来保证各个节点上 日志 的一致性。一个共识算法应该做到可以 保证所有节点上的状态机以相同的顺序执行相同的日志,最后得到相同的状态,产生相同的结果,达成共识 。
一个分布式共识算法,它应该具有以下 典型特征 :
- 在非拜占庭条件下保证安全(从不返回错误结果),非拜占庭条件指的是不考虑恶意节点的情况,但是包括网络延迟、分区、丢包、重复以及乱序等情况
- 可以容忍小于集群中 1/2 数量的节点挂掉,但系统整体功能完全正常
- 节点崩溃后可恢复
- 不依赖时序来保证日志的一致性
- 一条命令受到集群大多数节点的响应时,这条命令就算完成,少量响应慢的机器不影响整体系统的性能
以上便是共识算法的作用、特征及其在分布式系统中的地位,下面探讨分布式共识算法 Raft 的实现。
整体上来讲,Raft 算法可以分为几个模块,分别是:领导选举( Leader election ),日志复制( Log replication ) 以及 安全性(Safety) 。
一个运行着 Raft 算法的集群,会选举出来一个 Leader ,这个 Leader 全权负责日志的复制并将日志应用于状态机,这样简化了 日志复制 ,所有的日志流动是单向的,只会从 Leader 流向其他节点。
在 Raft 集群中,任意时刻,每个节点都处于下述三种状态之一:leader,follower 和 candidate 。
- leader :正常情况下,集群中同一时间只会有一个 leader
- follower :follower 是被动的,只会响应 leader 和 candidate 的
RPC消息 - candidate :在选举新的 leader 时会用到,是竞选 leader 的候选人
在 Raft 集群的初始状态,所有的节点状态都是 follower ,如果直到 election timeout 都没有收到来自 leader 的 AppendEntries RPC,也没有投票给某个 candidate , 则自动转入 candidate 状态。
注:election timeout 是选举超时时间,如果超过了这个时间还没有产生 leader,则认为目前没有 leader ,那么他自己成为 candidate ,请求投票竞选 leader;AppendEntries RPC是 leader 请求其他节点增加日志条目的 RPC消息;election timeout 是从一个范围内随机选取的,目的是为了避免两个节点同时变成 candidate 选举失败或者形成集群的分裂
转为 candidate 之后,立即开始选举,首先增大 term ,然后投票给自己,设置选举定时器,最后发送 RequestVote RPC 给所有其他节点。如果收到大多数节点的赞成票,则成为 leader ,如果收到了新 leader 的 AppendEntries RPC ,则转为 follower ,如果 election timeout ,则再次开始选举。
注:term 是 任期 ,Raft 将时间分为长度不定的任期,任期使用连续的整数表示,每一次选举的时候任期都会增加。任期是一个逻辑时钟,用于让各节点检测过期信息。每个节点都会存放当前任期,节点之间通信会携带任期号,如果一个节点发现自己任期落后,就更新任期;如果一个 _candidate 或者一个 leader 发现自己的任期过期,则自动切换为 follower ;如果节点收到了携带过期任期号的请求,会拒绝这个请求。RequestVote RPC 是 candidate 用来请求投票的 RPC 消息,一个节点在相同任期内只能投出一票_
当一个 candidate 赢得选举后,它成为 leader ,同时向其他节点发送心跳消息,建立权威。之后 leader 开始服务客户端请求,每收到一条来自客户端的日志,leader 首先首先把这条日志追加到自己的 log ,然后通过发送 AppendEntries RPC 消息将日志复制给其他节点。复制成功之后,leader 才会将这个日志条目应用到自己的状态机,并给客户端响应。leader 会对失联或者很慢的节点无限重试 AppendEntries RPC,直到所有的 follower 都复制了所有的日志.
Raft 的日志结构如下图所示:
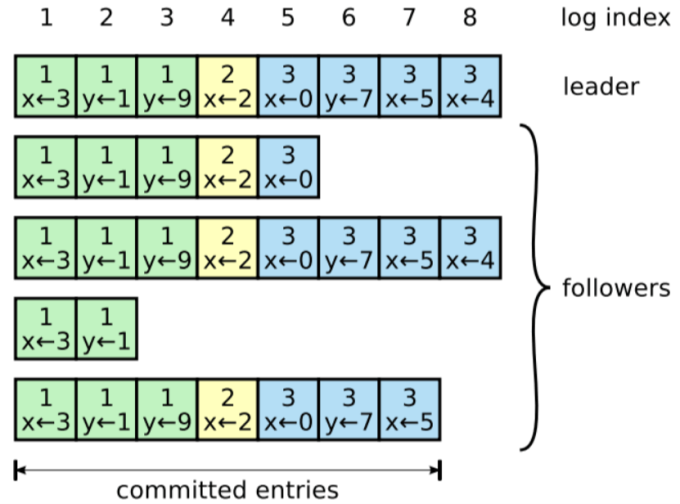
日志由日志条目组成,日志条目被顺序编号,标识其在日志中的索引( log index ),每个日志条目也携带 term ,图中位于最上方整数的便为日志索引,每条日志中的整数则为 term ,而日志中类似于 x<-3 的则为日志内容,日志内容会在日志复制成功后应用到状态机。
什么是 committed entries ? 简单来说,就是已提交日志条目,那么什么是提交( commit )呢?
只要这个日志条目已经在大多数节点上复制了,就认为这条日志已经提交了;这也暗含着,这个日志条目之前的所有日志条目都是已提交的。follower 一旦确定某个日志条目被提交了,就将这个日志条目应用到自己的状态机。
这样的设计可以保证不同节点的日志内容一致,称为 Log matching 。如果两份日志中有两个日志条目,他们的 log index 和 term 都相同,那么可以认为:
- 这两个日志条目一定包含了相同的命令。因为在给定 log index 和 term 的情况下,只可以定位到一个日志条目,所以如果存在,那么他们的内容一定相同。
- 在这两份日志中,从该 log index 往前的所有日志条目其内容都相同。这是通过
AppendEntries RPC中简单的一致性检查来保证的,AppendEntries RPC会携带上一条日志的 log index 和 term 信息,如果 flowwer 的日志的前一条日志并不与之相符,那么它会拒绝新的日志条目。
所以,如果一个 follower 接受了某一条日志,这意味着这条日志与 leader 的是一致的,也意味着前一条日志与 leader 是一致的,以此类推,它的整个日志都与 leader 是一致的。
在系统运行过程当中,由于 leader 挂掉等原因,会导致节点间的日志不一致,如何处理日志不一致呢?
Raft 的解决方式是使用 leader 的日志覆盖 follower 的日志,一旦发现 follower 中的日志与 leader 不一致,就会采取行动。
- 首先找到 leader 与 follower 最后一个共同认可的日志条目( 这暗示着这条日志以及之前的日志都一致,所以不用管)
- 将 follower 中从这条日志之后的日志都删除
- 将 leader 中从这条日志之后的日志都同步给 follower
这里有一个需要注意的特性是,leader 永远不会覆盖或者删除自己日志中的记录。
这里,你可能会有疑问,如果 leader 自己的记录就并不完整呢(也就是说选举出来的 leader 并没有包含全部的之前已经提交过的日志条目)?
幸运的是,Raft 已经考虑到了这点,它要求一个 term 的 leader 必须包含之前所有 leader 已经提交的日志,也就是说,当选 leader 的节点,它的日志条目一定是系统中最新的。
在请求投票时,RequestVote RPC 会包含发送方的日志信息,如果接收方发现自己的日志比发送方还要新,就会拒绝发送方成为 leader 的请求。
为了解决集群节点数量变化可能导致的集群分裂问题, Raft 采用两阶段方式,集群首先切换到一个 联合共识( joint consensus ) 的 事务型配置( transitional configuration ) ,一旦联合共识提交,系统就切换到 新配置 。在这个过程中,集群不会丢失可用性,仍然能继续服务客户端请求。
在 Raft 集群中,客户端会将所有的请求都发给 leader ,但是很多时候客户端并不知道 leader 是谁,那怎么办? 实际上,客户端会随机选择一个 Raft 节点进行连接,如果连接的节点是 leader ,它会直接处理请求;如果连接的节点不是 leader ,则会拒绝这个请求,并把连接重定向到 leader 。
至此,分布式共识算法 Raft 的核心机制已经在本文中探讨了,如果有问题,可在评论区讨论~
下面我们讨论一下 Raft 算法的一致性保证,Raft 号称是可以保证 强一致性 的算法,我们先来看看强/弱一致性的定义:
Strong consistency – ensures that only consistent state can be seen.
- All replicas return the same value when queried for the attribute of an object All replicas return the same value when queried for the attribute of an object. This may be achieved at a cost – high latency.
强一致性 保证只有一致性的状态才能被客户端看到,也就是说,查询所有副本返回的数据应该是一致的,但是这也会带来代价——较高的延迟。
Weak consistency – for when the “fast access” requirement dominates.
- update some replica, e.g. the closest or some designated replica
- the updated replica sends up date messages to all other replicas
- different replicas can return different values for the queried attribute of the object the value should be returned, or “not known”, with a timestamp
- in the long term all updates must propagate to all replicas …….
- consider failure and restart procedures,
- consider order of arrival,
- consider possible conflicting updates consider possible conflicting updates
弱一致性 适用于需要低延迟的场景,它首先更新一个副本,由这个副本去更新其他的副本,不同的副本会返回不一致的数据,GFS( The Google File System ) 就采用了这样仅保证弱一致性的算法。
Raft 是保证强一致性的,也就是说,在日志 提交( commit ) 之后,我们去访问 Raft 集群,得到的返回一定是最新的且一致的。
实际上,Raft 在大多数节点都成功复制了一条日志之后,就认为这条日志已经提交了,很显然,此时集群中的所有节点的日志并不止一致的,那么 Raft 的强一致性是如何保证的呢?
我认为这是由客户端仅与 leader 通信保证的,虽然客户端可以连接集群中的任意一个节点,但是最后都会被转发给 leader ,Raft 通过 leader 来保证 强一致性 ,即实现访问的一定是最新的数据,且每次访问得到的结果都是一致的。